Intro
Job searching is hard. Anybody looking for one knows how draining it can be to sift through endless listings, hoping to find something that fits or feels right. Ain’t nobody got time for dat…
Instead, we use agents 🤖 to keep track of openings at companies we care about and in departments we want to work in. The challenge is, not every company offers a 🔔 / 📩 / to notify you when new positions open up. And even when they do, how often do you actually check those newsletters? Thought so! 😉
With ✨agentic job search✨, you get a streamlined report of all the current openings at companies you’re interested in, tailored to the departments you want to work in. This is made possible by web scraping combined with agents—specialized programs that can run tasks independently and make decisions without human intervention. For this project, we rely on CrewAI, one of the leading agentic frameworks out there. It brings together multiple specialized AI agents into a collaborative team, letting them work together smoothly to tackle complex tasks. Think of it as an AI squad with defined roles and workflows, functioning much like a well-oiled team.
The inspiration for this project came from one of the use cases demoed in crewAI’s courses on deeplearning.ai. I highly recommend checking them out. Their approach to job searching is a bit different and more generic but equally powerful.
Prerequisites
Before diving in, you’ll need:
- Technical Skills: Basic Python knowledge, familiarity with HTML/CSS, command-line operations
- System Requirements: Python 3.10+, 4GB+ RAM (16GB+ recommended for local LLMs along with a supporting GPU)
- API Access: Account with any cloud LLM provider (optional if using Ollama)
- Time Investment: 30-45 minutes for initial setup, a few minutes per run thereafter
This guide targets intermediate developers comfortable with web scraping concepts and API integrations.
Web Scraping
Before we look at what 🤖 do, we need to look at the good’ol web scraping. The idea is simple. You create a list of your favorite organizations and a department/sector that you’d like to filter for. Then you scrape the for the latest openings and store it on disk. (We use Playwright package for this) After that, the 🤖 steps in to sift through these roles and handpick the ones that match your interests.
There are a few good reasons why we can’t just tell an agent to hop onto a website and grab the latest job postings directly:
- The large language model (LLM) the agent relies on might not be powerful enough to fully get the instructions or might miss parts of the content—after all, not everyone’s got access to OpenAI’s top-tier models!
- Dynamic content on job listing pages can trip up the model. Sometimes the section you want isn’t even loaded yet when the agent tries to fetch it, especially since many organizations use third-party platforms like Ashby or Workable that embed listings via JavaScript.
- Some websites are massive, with an overwhelming number of openings across multiple locations, making it tough to scrape everything efficiently.
- Models can hallucinate—meaning the job listings they generate might look legit but actually be inaccurate, outdated, or just plain wrong based on their training data or knowledge cut-off.
That’s why the scraping step here is crucial. To make it manageable, we create a YAML file where we define specific attributes that help us target and fetch the right content later on.
Here’s a sample:
#orgs.yaml sample file
browser_company:
url: https://jobs.ashbyhq.com/The%20Browser%20Company
selector: "div._departments_12ylk_345"
ecosia:
url: https://jobs.ashbyhq.com/ecosia.org
selector: "#root > div._container_ud4nd_29._section_12ylk_341 > div._content_ud4nd_71 > div._departments_12ylk_345"
mozilla:
url: https://www.mozilla.org/en-US/careers/listings/
selector: '#listings-positions tbody tr.position[data-team="Strategy, Operations, Data & Ads"]'The key here is the organization name you’re interested in, and the values hold the URL plus a selector. These are CSS patterns that identify specific HTML elements on a webpage, so you can zero in on the exact part you want to scrape.
Finding the right selector is usually straightforward but sometimes can be a bit tricky. If the webpage uses dynamic content, wait until the job listings or tables have fully loaded, then right-click on the listing area and choose Inspect. That opens the developer tools where you can explore the DOM tree. Move up or down through parent and child elements until you spot the container holding the data. As you click on different elements, they’ll highlight corresponding webpage parts, helping you confirm you got the right one. Finally, right click on the element (or on the … dots at the start of the line), and choose copy -> copy selector as shown below.
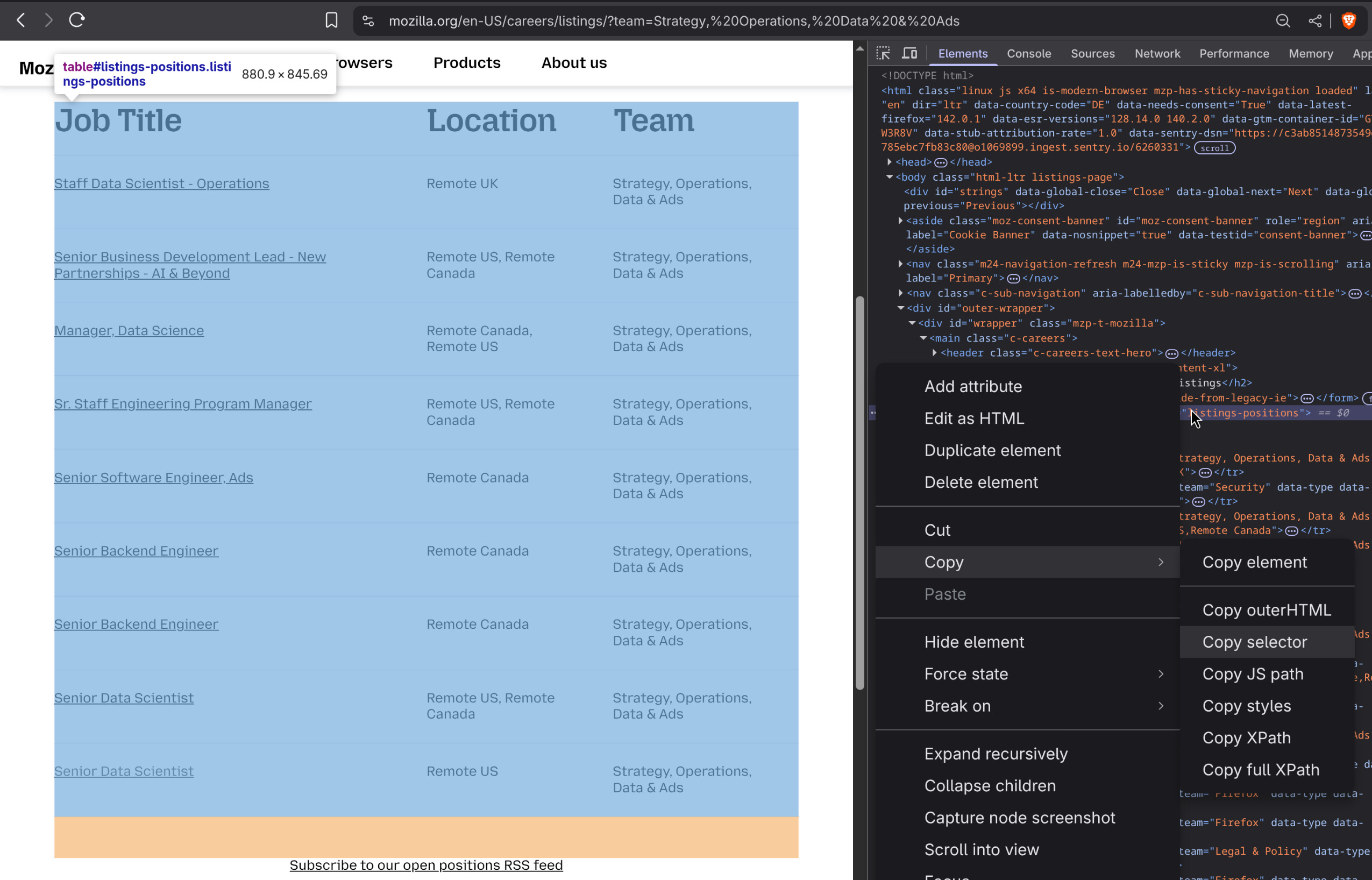
Using the selector approach has several key advantages:
- It enables scraping of targeted and precise content—you download just the data you need, or at most a manageable superset that can be filtered later by an agent or LLM.
- It’s reliable because website layouts don’t change that often. When they do, you simply update the selector in the YAML file, and you’re good to go (well, almost!). Plus, the program logs failures if scraping doesn’t work, so you can jump in and fix it manually.
- It allows for a highly effective, yet optional, use of a powerful model—since we feed the LLM only the stripped-down HTML content, even mid-sized models can deliver great results.
This method ensures the 🤖 always work with the freshest and cleanest data, making filtering faster, simpler, and more accurate. They’re happy, you’re happy! Now, let’s see how it all comes together.
The complete code and installation instructions are available on . Head over there to setup the repo, then come back, and we’ll dive into the details!
Run with agents
Hopefully, you’re now set up. You only needed to do three things:
- Make sure the creds.yaml file is filled with the credentials for your favorite LLM.
- While it currently supports three providers out of the box, adding another cloud provider—like Anthropic—is as simple as adding the corresponding entries to the file and passing the provider name as an argument to main.py.
- Different providers make different env variables available apart from common ones like
API_KEY. Simply add them under the corresponding provider in the YAML file.
- Populate the orgs.yaml file with your favorite organizations.
- Set the
JOB_TOPICvalue in src/config.py with a topic or department you want to filter roles for. Alternatively, you can pass this as a parameter directly to the main.py script.
With these in place, you’re ready to roll!! 🥁
If you want to do LLM inferencing locally or from a remote endpoint, checkout the 🦙ollama🦙 section below.
To run your setup, simply do:
crewai runIf you run into any errors, the first place to check is the logs.log file—it’s where all the action gets recorded. And if you bump into a ModuleNotFoundError or your command won’t execute properly, try running this command instead:
PYHONPATH='.' uv run run_crewThe completed jobs report is available under src/scrape/jobs directory. Here’s a sample:
[
{
"org": "mozilla",
"url": "https://www.mozilla.org/en-US/careers/listings/",
"jobs": [
{
"title": "Staff Data Scientist - Operations",
"href": "https://www.mozilla.org/en-US/careers/position/gh/7141659/",
"location": "Remote UK",
"workplaceType": null
},
{
"title": "Manager, Data Science",
"href": "https://www.mozilla.org/en-US/careers/position/gh/6989335/",
"location": "Remote Canada, Remote US",
"workplaceType": null
},
{
"title": "Senior Data Scientist",
"href": "https://www.mozilla.org/en-US/careers/position/gh/7125910/",
"location": "Remote Canada, Remote US",
"workplaceType": null
},
{
"title": "Senior Data Scientist",
"href": "https://www.mozilla.org/en-US/careers/position/gh/7137777/",
"location": "Remote US",
"workplaceType": null
}
]
},
{
"org": "ecosia",
"url": "https://jobs.ashbyhq.com/ecosia.org",
"jobs": []
},
...
]Sweet!!! Now, all that’s left is to browse through the filtered roles at your favorite companies, click on the listings you’re genuinely interested in, and maybe even apply—all while comfortably sipping your ☕️ with one hand. 😎
That said, this setup works best if you have access to a decent model from a reliable cloud provider—but those don’t come cheap. CrewAI agents make multiple calls to the LLM for each organization (including tool calls), so if you’re not on a generous plan, the tokens consumed and requests made can quickly add up, especially as you add more companies to your YAML file.
It gets trickier if the scraper can’t locate your specified selector and ends up scraping the entire page as a fallback, or if the listings come from a large company and you forgot to include adequate filters in your selector. Feeding huge chunks of HTML content—beyond just the system and assistant prompts—🔥 through tokens fast. And even worse, if the model makes a mistake, you often have to feed its response back into the system, which further increases both calls and token usage.
For those without a paid subscription, there are alternatives like openrouter and AIML, though the free tiers are quite restrictive. These options work well for manual testing but aren’t suited for the high volume of calls that CrewAI requires. If you need to handle larger workloads, you might want to explore the Programmatic approach section optionally combined with ollama for better efficiency.
Ollama
If you have a (beefy) system at home or access to one, you can then run LLMs locally with ollama. Their extensive library offers a range of models that can comfortably run on your hardware for inference tasks. We won’t cover its installation and pre-requisites but assume that it’s already setup on your system, which you can check by running which ollama.
With my 💻 config, I was able to run gpt-oss:20b after closing all other applications, but the model response time remained quite low. It might be fine for having a (patient) conversation but isn’t fast enough to run our agents effectively. That said, as mentioned earlier, we don’t necessarily need a highly advanced (reasoning) model for this use case since the tasks aren’t that complex.
What we really need is a model that runs comfortably on our systems and is preferably trained on code. So, I settled on Qwen2.5-coder, which showed strong performance on various coding tasks and programming languages. Of course, feel free to pick whichever model suits your needs best!
With ollama, you don’t need an API key to run it locally. So you can skip the OLLAMA_API_KEY in the creds.yaml file but make sure you fill up the rest.
When running an Ollama model locally, you can use it to power your agents instead of relying on expensive cloud providers. Just change the provider name to OLLAMA in the main.py file suggested earlier (assuming you’ve set up its credentials in creds.yaml).
Programmatic Job Search
Alternatively, you can bypass the agentic workflow altogether and opt for a programmatic approach that sequentially processes each organization to fetch job listings. This method supports using your preferred cloud provider or a local ollama model. Simply configure the appropriate provider along with any optional parameters. To execute the programmatic fetch, run:
uv run run_manualUnfortunately, I could only test my setup with free cloud providers and with ollama. If in case you face errors, please raise an issue on so that it might be resolved with community’s help.
Metrics
On my rig, scraping only took a couple of seconds per organization and about 30s for inferencing and preparing the job report with qwen2.5-coder & ollama per organization. The tokens per second roughly hovered between 6-10 and the response time is usually under 5 seconds. The input prompt tokens roughly are in a couple of thousands (less than 5K) because we send a blob of HTML but the response tokens relatively are far less - roughly around 500. For orgs with no listings, it’s negligible (<10). YMMV
If doing local LLM inferencing, you can check your metrics in the logs whenever the model makes an inference.
Next Steps or Customization
Thanks for sticking with me this far! If you only need a bare-bones working version, you might want to stop here. But of course, there’s plenty of room to ⚗️🧪 and expand. We’ve used just one 🤖 and one task ✅️, but feel free to add more.
For example, you could do additional post-processing on the final report—convert it to markdown, filter roles further by location or workplace type, or even make another LLM call to summarize the entire report 🤯. You could also set up an alert system, like a hook, to get your daily job report delivered automatically. ✨️
If you want to go really deep, you could filter the returned role ⛓️💥, scrape those pages for content, and then use a powerful LLM to customize cover letters for each application. Or, keep it visual 📊 to analyze the scraped data.
Go 🥜🥜🥜!!! But remember to use this work responsibly and for personal use only.
Please feel free to ⭐ the repo on , fork it to tweak further and/or provide feedback.
Auf Wiedersehen! 👋