How we can leverage advances in machine learning for biodiversity conservation among others
EDA
pytorch
biodiversity
conservation
spectrograms
bioacoustics
Published
January 8, 2026
Identifying birdcalls with deeplearning
Over a million species face extinction right now and we’re losing species faster than we can count them. While rainforests capture the spotlight, a quieter extinction is happening all around us—in the soundscapes we barely notice. Organizations such as Earth Species Initiative, Hula, Biometrio etc. aren’t waiting for boots on the ground to disappear into the wilderness; they’re training AI to listen instead.
Why & How?
What if you could monitor an entire ecosystem without stepping foot in it? A single passive acoustic monitor—a battery-powered device no bigger than a shoebox—can listen 24/7, capturing the calls of species too shy to let humans near them. Deploy a network of them, pair their recordings with machine learning models trained on repositories like Xeno-canto’s 1+ million bird recordings, and suddenly you can track biodiversity across landscapes faster and cheaper than traditional field surveys ever allowed. That’s the promise of passive acoustic monitoring: turning the invisible language of nature into quantifiable conservation data. In this guide, we’ll try to build our own deep learning model to do exactly that.
Deep learning already leveraging acoustics data to try to find known bird calls - presence and diversity of birds and other animals is a sign of healthy bio-diversity - increasingly, we are also trying to detect in-species sounds:
The following tutorial is based on this github repo that I created where you can find more information.
To download metadata of recordings programatically from Xeno-Canto, you’d need an API key that’s freely available once you register.
I’m interested in identifying bird species in a small region and for that we can train a simple deeplearning model. Instead of training a model on the recordings from a small region, for which we may or may not have enough data, we instead find out which birds are typically found in the said region and try to get recordings for those species from a wider area (e.g., a city/country/continent etc.). Then we can test it to identify birds in our narrow region.
I’m interested in Munich city but first, let’s find out how many recordings for birds we have for Germany…
Wow! we have ~36K recordings of 340 different species of birds… that’s very interesting. Can’t analyse all here… so let’s take a subset from Munich… We draw a bounding box
cnt
France 0.203860
Sweden 0.187719
Spain 0.092281
Poland 0.083860
United Kingdom 0.069825
Germany 0.053684
Netherlands 0.041754
Italy 0.035789
Norway 0.025965
Portugal 0.019298
Name: proportion, dtype: float64
Interesting! Most of the recordings for the birds that I am interested in from Munich comes not from Germany but from neighbouring countries… this provides insights as to the habitat spread of a species of interest.
We will use librosa to handle loading audio of various formats. Make sure ffmpeg is installed in your system.
y, sr = load_audio(sample_audio)y.shape, sr
((2009408,), 44100)
This 45 second clip contains more than 2M data points because of the high sampling rate.
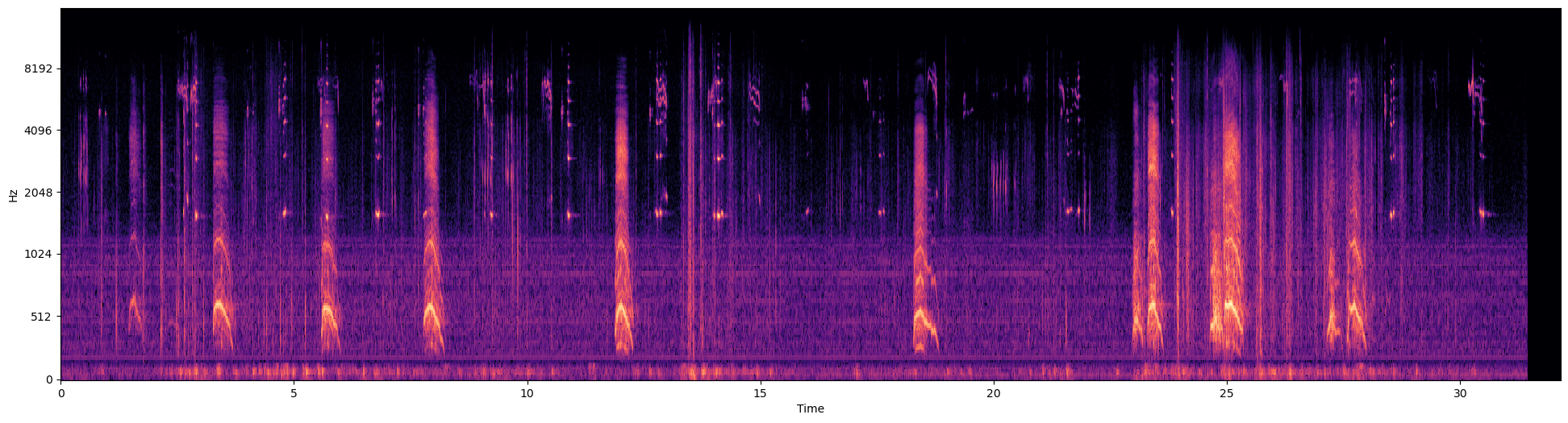
We shall now extract mel-spectrogram from the wave data. There’re many articles out there explaining these, so I would refrain from going into detail. In short, audio is an analog signal that we convert into digital format with a certain sampling rate. Because it is a signal, we can run Fourier Transforms (FT) to decompose it into individual frequencies. But given the non-periodic nature of human speech or bird calls etc., we instead do STFT (Short Time FT) over a window. There can be many frequencies overlapping at any given point of time and these can be visualized as a spectrogram. Because of the non-linear nature of our innate hearing capabilities & constraints, we convert these frequencies to Mel Scale. Mel-Spectrograms are just that.
mel_dB = get_melspec(y, sr, plot=True)
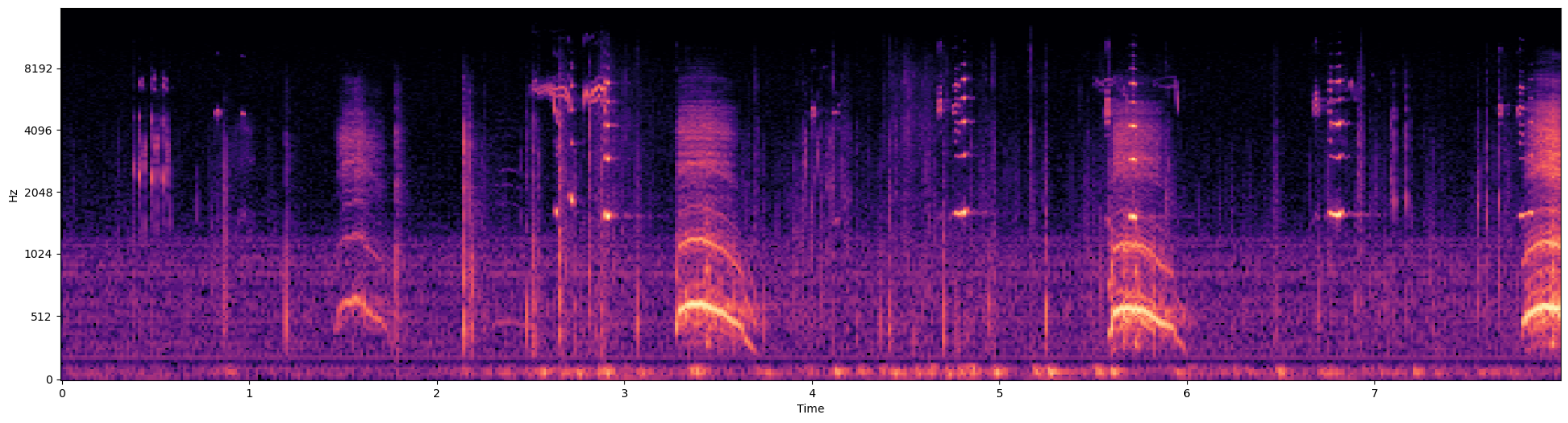
Let’s zoom into a small section to see more details of the harmonics or overtones…
the metadata also includes other bird (& animal?) species that also appear in a given recording. We can also leverage these when doing multi label classification.
Train Model
We will build a very simple starter ResNet based model to identify birds calls/songs but this can be adapted to any species. It works the following way:
Obtain MelSpectrograms of the audio recordings of your species of interest
During training:
randomly extract n seconds of audio data from the whole audio file
generate mel-spectrogram of it
pre-process and transform it into a single channel image (a square array)
train on these patches
We keep the pretrained weights, freeze the resnet backbone and adjust the no. of last linear layer’s output features to the no. of classes we have in our dataset. We also change the inputs of the first CNN layer given that we have a single channel image.
device ='cuda'if torch.cuda.is_available() else'cpu'mdl = Model(device, pretrained=True, freeze_backbone=True)mdl.set_dataloaders("data/train_audio/", batch_size=32)for x, y in mdl.train_dl:breakx.shape, y.shape
The model’s also hosted as a demo on huggingface spaces: munich-bird-identifier although keep in mind that the results aren’t that accurate as it’s just a PoC.
Next Steps:
Our current model barely scratches the surface. It just represents one of the many approaches for understanding how deep learning tackles bioacoustics. However, the field is advancing rapidly, and there are numerous directions to extend and enhance our approach.
Real-world bird classification demands moving beyond single-channel, binary classification models toward greater sophistication. We can do that by incorporating multi-channel spectrograms that capture complementary acoustic features (Mel-spectrograms at varying resolutions, delta features, chromagrams), then expand to multi-label scenarios where multiple species vocalize simultaneously. On top of that, we can develop multimodal models fusing acoustic data with temporal (time of day, season), spatial, and weather metadata; information that dramatically improves predictions since bird activity patterns are highly context-dependent. Google’s Massive Sound Embedding Benchmark (MSEB), presented at NeurIPS 2025, provides an extensible framework for evaluating such multimodal sound models, with BirdSet demonstrating how bioacoustics integrates into broader auditory intelligence research.
We also have to understand the resource constraints such as compute, power etc. when deploying models on to edge devices where light-weight models such as EfficientNet shines.
Standardized benchmarks like BirdSet become essential for validating progress against state-of-the-art approaches. BirdSet aggregates diverse datasets into a unified framework exposing models to both focal recordings (isolated calls from Xeno-Canto) and soundscape recordings (complex passive monitoring data), explicitly testing for the “covariate shift” problem where models trained on clean recordings struggle with real-world acoustic environments. By evaluating against BirdSet’s standardized pipeline and baseline results, we can quickly identify strengths and weaknesses in our model. Additionally, MSEB’s inclusion of BirdSet enables evaluation across downstream tasks beyond classification such as acoustic retrieval, clustering unknown species, and temporal segmentation of vocalizations within long recordings. Google’s Perch 2.0 model released recently got SoTA results on this dataset.
Apart from that, kaggle also hosts annual BirdCLEF competitions for bioacoustics wherein massive soundscape datasets get dissected by top teams who then publish their full solution writeups as open-source treasure. This knowledge sharing featuring cutting-edge techniques seeps straight from notebooks into real-world conservation tools. With models and datasets like these, only our imagination limits what we can achieve towards conservation of biodiversity.